

Seedream 3.0 marks a major leap forward in AI-driven image generation, particularly for Chinese-English bilingual contexts. Building on the success of Seedream 2.0, the latest release tackles long-standing challenges—ranging from text rendering and visual aesthetics to resolution constraints—through innovations spanning data processing, model architecture, post-training optimization, and inference acceleration. The result is a model that not only competes with but often surpasses industry leaders like Midjourney v6.1, Imagen 3, and GPT-4o in multiple benchmarks.
Data: Bigger, Cleaner, Smarter
One of the core upgrades in Seedream 3.0 is its defect-aware training paradigm. Instead of discarding imperfect images, the model selectively retains them if defects cover less than 20% of the frame—masking problem areas during training to preserve valuable information. This approach alone expanded the dataset by 21.7% without compromising stability.
Data selection is further enhanced by a dual-axis collaborative sampling framework, balancing both visual diversity (through hierarchical clustering) and textual semantic coverage (via TF-IDF). A cross-modal retrieval system ensures high-quality image-text pairings, enabling better prompt alignment and richer concept representation.
Architecture & Pre-training: Cross-Modality Meets Scalability
Seedream 3.0 builds on its MMDiT backbone with key innovations:
- Mixed-Resolution Training: Images of varied resolutions and aspect ratios are trained together, boosting generalization to new formats.
- Cross-Modality RoPE: Extends rotary position embedding to align visual and text tokens more effectively, crucial for accurate text rendering.
- Representation Alignment Loss: Aligns model features with those from a pretrained vision encoder (DINOv2-L), accelerating convergence.
- Resolution-Aware Timestep Sampling: Adapts diffusion timestep distribution based on resolution, improving high-res synthesis quality.
Post-Training: Aligning with Human Aesthetics
To make outputs not only accurate but also visually appealing, Seedream 3.0 integrates diversified aesthetic captionsduring supervised fine-tuning. These captions include detailed descriptors of style, layout, and mood, enabling more precise control in prompt engineering.
A major shift from Seedream 2.0 is the move from CLIP-based reward models to Vision-Language Models (VLMs) for reinforcement learning with human feedback. Scaling the reward model from 1B to over 20B parameters led to measurable improvements in preference alignment and output quality.
Inference Acceleration: 1K Images in 3 Seconds

One of the standout features of Seedream 3.0 is its 4–8× speedup without quality loss. This is achieved through:
- Consistent Noise Expectation: Maintains stable denoising across timesteps, enabling fewer steps while preserving fidelity.
- Importance-Aware Timestep Sampling: Learns which timesteps matter most for quality, focusing computation there.
- Adaptive Trajectories: Customizes generation paths for each sample, reducing randomness and improving diversity.
The result: 1K resolution images in just 3.0 seconds, with native support for 2K resolution and higher.
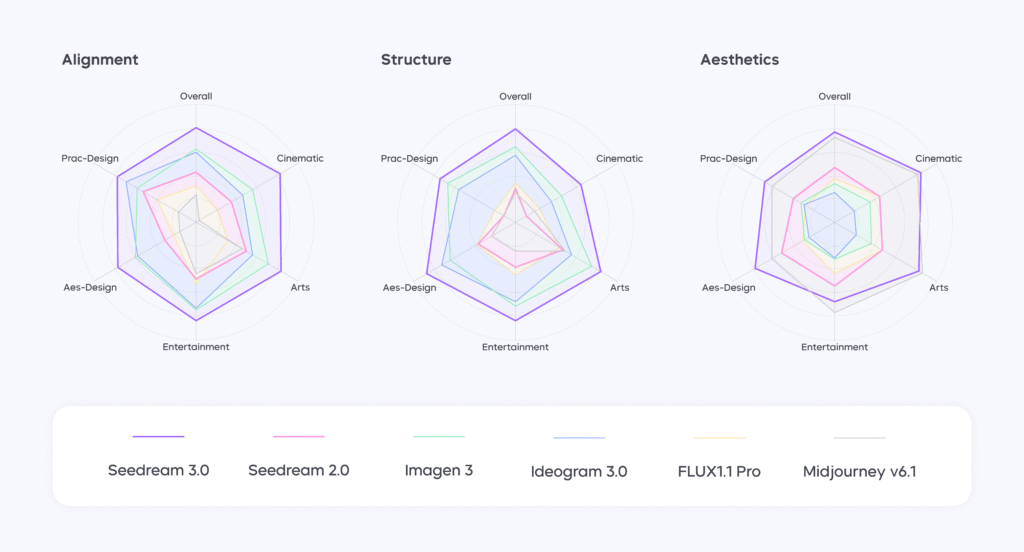
Benchmark Performance: Leading Across the Board
On Artificial Analysis Arena, a global leaderboard for text-to-image models, Seedream 3.0 achieved an ELO score of 1158, securing first place against models like GPT-4o, Imagen 3, and Midjourney v6.1. It excelled in both style categories (photorealistic, anime, traditional art) and subject categories (portraits, fantasy, physical spaces).
Text Rendering: Achieved a 94% availability rate for both Chinese and English, with exceptional performance in dense, small-text scenarios—outperforming GPT-4o in Chinese typography and typesetting.
Portrait Realism: Matched Midjourney v6.1 in public Elo-based evaluations while offering superior texture detail, lifelike skin tones, and high-resolution clarity.
Automatic Metrics: Ranked first in EvalMuse, HPSv2, MPS, and internal alignment/aesthetic scores, showing consistency with human preferences.
GPT-4o vs. Seedream 3.0: Different Strengths
In head-to-head comparisons:
- Dense Text: Seedream 3.0 excels in Chinese characters and overall layout; GPT-4o performs well in small English text and math symbols.
- Image Editing: Seedream’s SeedEdit tool balances identity preservation with accurate edits, outperforming GPT-4o in maintaining visual consistency.
- Generation Quality: GPT-4o outputs sometimes suffer from color casts and noise, while Seedream maintains cleaner, more balanced visuals.
The Takeaway
Seedream 3.0 isn’t just an incremental upgrade—it’s a full-stack overhaul of data, architecture, training, and inference that delivers faster, higher-quality, and more accurate bilingual image generation. With native high-resolution output, unmatched Chinese text rendering, and industry-leading performance benchmarks, it sets a new standard for multimodal AI creativity.
The model is already live on platforms like Doubao and Jimeng, where it’s being used for everything from professional design work to cinematic concept art. If Seedream 2.0 proved the concept, Seedream 3.0 makes it production-ready.